The Control Theory Behind Harness Engineering: A First-Principles Map
I was three weeks into building a product detail page generation system for an ecommerce project when I noticed something odd about my own behavior. I had a chat agent wired up with extended tools for inventory lookup, pricing rules, and content generation. The agent worked. What I couldn't figure out was why I'd spent maybe 20% of my time writing prompts and 80% of my time designing the environment around the agent. Linter configs. Structured output schemas. Validation scripts that checked whether generated PDP content matched actual inventory state. Feedback loops that caught when the agent hallucinated a product attribute that didn't exist in the catalog.
I kept thinking I was doing something wrong. That I should be spending more time on the prompts. Then I read how OpenAI, Stripe, and Anthropic were building their agent systems, and realized they were all doing the same thing. They just had a name for it.
I wasn't prompting. I was engineering a control system.
That realization is what this article is about. Not "AI agents are changing software," which is obvious to anyone paying attention, but the specific shape of the engineering discipline forming around them. I've spent the last few weeks reading everything I could find from teams actually doing this at scale, and the pattern that keeps showing up is control theory. Not metaphorically. Literally. The moment you see harness engineering through that lens, the entire field clicks into place.
What is a harness, mechanically?
Start from the atoms. An LLM is a function: tokens in, tokens out. Stateless. No memory between calls. An agent is that function placed inside a loop with access to tools. The loop goes: receive task, call model, model requests a tool, execute tool, feed result back to model, repeat until done.
The agent loop is simple. What makes it useful or useless is everything around the loop. The context it receives. The tools it can call. The constraints on what it can and cannot do. The feedback that tells it whether what it did actually worked.
That "everything around the loop" is the harness.
Mitchell Hashimoto, creator of Terraform and Ghostty, put a name to this earlier this year. His definition is practical: anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again. The harness is the accumulated result of that process.
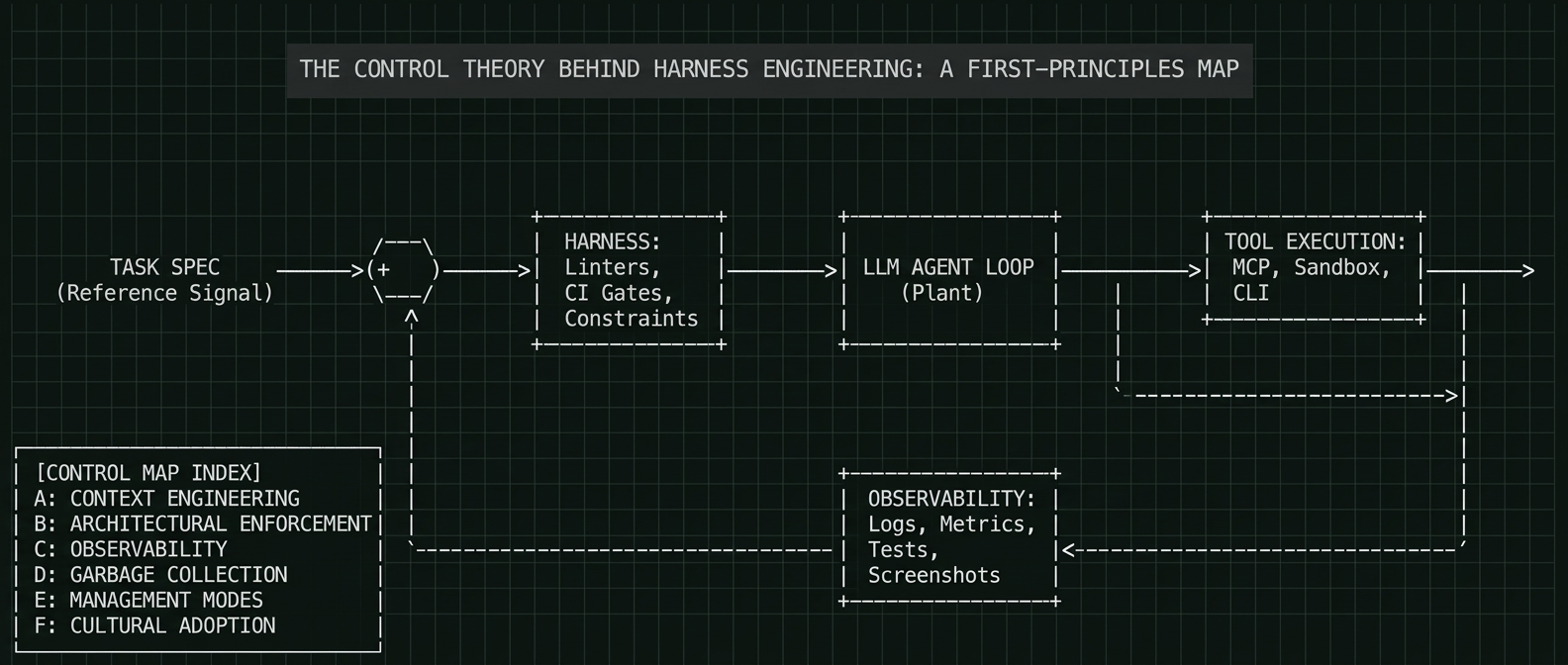
But I think there's a more precise way to frame it. In classical control theory, you have four components: a plant (the system being controlled), a controller (the logic that directs it), sensors (the feedback channel), and a reference signal (the desired outcome). Map that onto agent systems and the correspondence is almost eerie:
The LLM is the plant. It generates output. The harness is the controller. It constrains, directs, and corrects. Observability (logs, metrics, tests, screenshots) are the sensors. The task specification is the reference signal.
Open-loop control means you send a command and hope for the best. That's what most people are doing with agents right now. You type a task, the agent runs, you get output, you pray.
Closed-loop control means the output feeds back into the input and the system self-corrects. That's what harness engineering actually builds. And it's why the teams building real systems at scale have converged on such similar architectures despite working completely independently.
Every success story I've found is a team that figured out how to close the loop. Every failure is a team running open-loop and wondering why the output drifts.
The landscape, built from problems
The interesting thing about the teams doing this well is that they didn't start with a framework or a taxonomy. They started with a problem, solved it, and discovered that solving it created the next problem. The landscape of harness engineering isn't a list of independent topics. It's a chain of problems where each solution reveals the next constraint.
Here's the chain as I understand it.
Problem 1: The agent is blind
An agent can only reason about what's inside its context window. Everything else might as well not exist. Slack conversations, Google Docs, the architectural decision your team made last Tuesday over coffee: invisible. This is the same problem you'd have if you dropped a new hire into a codebase with zero onboarding, except the new hire has no memory and will forget everything the moment the session ends.
The first instinct is to write a big instruction file. Almost everyone tries this. Hashimoto maintains an AGENTS.md for Ghostty where each line corresponds to a specific past agent failure that's now prevented. It's essentially an immune system: every mistake becomes a vaccination. OpenAI tried a more comprehensive version and loaded it into every session. It failed predictably. A giant instruction file competes with the actual task for context window space. When everything is marked "important," the agent pattern-matches locally instead of navigating intentionally. And the file rots within days because nobody maintains a 1,000-line document that only an AI reads.
The fix that multiple teams converged on independently: make the instruction file a table of contents, not an encyclopedia. OpenAI's AGENTS.md is roughly 100 lines that point to deeper sources of truth stored in a structured docs directory. Design documents, architecture maps, execution plans, quality grades. All versioned in the repo. All mechanically validated by CI to ensure they're cross-linked and current. A background agent periodically scans for stale documentation and opens cleanup PRs.
This is the first closed loop: documentation that maintains itself.
Anthropic's team found the same problem from the other direction. Their long-running agents would start each session with no memory of prior work. The solution was structured progress files and feature lists, essentially shift-handoff documents so a new agent could pick up where the last one stopped. They found that JSON worked better than Markdown for this because agents were less likely to accidentally edit or overwrite structured data. Different solution, same underlying insight.
Boris Tane, who previously lead Workers observability at Cloudflare, takes an even more opinionated stance: never let agents write code until you've reviewed and approved a written plan. His reasoning is that planning is itself a form of context engineering. When you force the agent to articulate what it's about to do, you're creating a reference signal you can actually evaluate before any code exists.
The general principle: you don't give agents knowledge. You give them a map and teach them where to look. Progressive disclosure, not information dumping.
Problem 2: The agent ignores boundaries
Context helps the agent understand the codebase. It does not prevent the agent from violating architectural decisions. An agent with access to every file in a repo will happily create circular dependencies, bypass abstraction layers, and import from packages it shouldn't touch. Not out of malice. It simply has no concept of "should" unless you make "should" mechanically enforceable.
Every team that has succeeded at scale arrived at some version of the same solution: rigid constraints, enforced by tooling, not by documentation or convention.
OpenAI built a strict layered dependency model. Types, then Config, then Repo, then Service, then Runtime, then UI. Cross-cutting concerns enter through a single interface called Providers. Everything else is disallowed. Stripe took a different path to the same destination. Their Minions run in isolated devboxes, the same development environments human engineers use, with access to internal tools through a centralized MCP server called Toolshed. Toolshed contains nearly 500 tools, but here's the critical design choice: the system doesn't expose all 500 to the agent. A deterministic orchestrator scans the task, identifies relevant context, and curates a subset of roughly 15 tools before the agent even activates. Too many tools causes what you might call token paralysis. The agent wastes cycles figuring out which tool to use instead of doing the work.
Both teams invested heavily in linters, but the clever part isn't the linting itself. It's that the error messages are written as remediation instructions that get injected directly into the agent's context. When the agent breaks a rule, the tooling teaches it how to fix the violation in the same breath. The system is blocking mistakes and training the agent simultaneously. CodeScene, who've been building code health analysis for years, calls this pattern "making architecture enforceable, not just documented."
Birgitta Böckeler at Thoughtworks pointed out something counterintuitive about all this: increasing trust and reliability in AI-generated code requires constraining the solution space rather than expanding it. We might end up choosing tech stacks and codebase structures not because they're the most flexible, but because they're the most harness-friendly. OpenAI's team leaned toward what they called "boring" technology for exactly this reason: composable libraries with stable APIs and strong representation in the model's training data.
In a human-first workflow, rules this rigid feel pedantic. With agents, they're multipliers. Encode a constraint once and it applies to every line of code the agent writes from that point forward.
Problem 3: The agent can't tell if it worked (evals, evals, evals)
This is where the landscape gets interesting, because this is where most teams are stuck.
Your agent respects architectural boundaries. It follows naming conventions. It generates code that passes linting. But does the code actually do what it's supposed to do? Structural quality and behavioral correctness are completely different things, and most of the harness engineering conversation focuses on the first while quietly ignoring the second.
OpenAI's team addressed this by making their application directly inspectable by agents. Each git worktree can boot its own instance of the app. They wired Chrome DevTools Protocol into the agent runtime so agents could take DOM snapshots, capture screenshots, navigate the UI, and reproduce bugs. They spun up a local observability stack exposing logs via LogQL, metrics via PromQL, and traces via TraceQL. A prompt like "startup should complete under 800ms" went from aspirational to measurable.
This is sensor engineering. In a control system, you can only correct for what you can measure. If the agent has no way to observe the effect of its own output, you're running open-loop on behavioral correctness even if you're closed-loop on structural quality.
Birgitta Böckeler at Thoughtworks identified this as the biggest gap in OpenAI's writeup. Their article describes extensive verification of structure but says almost nothing about verification of behavior. Anthropic's long-running agent research found the same gap independently: agents would mark features as complete without proper end-to-end testing and, absent explicit prompting, would fail to recognize that something didn't work. CodeScene's team put it bluntly: AI often writes code it cannot reliably maintain later, and agents have no way to verify whether their changes are objectively better or just a different arrangement of the same complexity.
The can.ac blog drove this point home with benchmarks. A researcher showed that the edit format alone, just how you tell the agent to apply changes, swung model performance by 5 to 14 percentage points across 15 different models. The agent's ability to produce correct output is deeply entangled with harness mechanics that most teams treat as an afterthought.
This is the frontier. And it's not a model problem. Better models won't solve it. It's a harness problem: you need to build sensors that let the agent observe its own behavioral output, and then close the loop by feeding those observations back into the next iteration.
Problem 4: The codebase rots anyway
Suppose you've solved problems 1 through 3. The agent has context, respects boundaries, and can validate its work. The codebase still rots.
Agent-generated code accumulates technical debt differently than human-written code. The patterns are subtler: slight inconsistencies in approach across files, dead code that nobody realizes is dead because nobody wrote it, gradual drift from architectural conventions that individually look fine but collectively degrade the codebase. As one analysis on mtrajan's Substack put it: context engineering asks what the agent should see. Harness engineering asks what the system should prevent, measure, and correct. This is the "correct" part.
OpenAI's team initially spent about 20% of their week, every Friday, manually cleaning what they called "AI slop." Then they did the obvious thing: they codified their cleanup principles and automated the cleanup as background Codex tasks. Agents now scan for deviations from "golden principles" on a regular cadence, update quality grades for each product domain and architectural layer, and open targeted refactoring PRs. Most get auto-merged.
Stripe addresses a version of the same problem at a different scale. Their Minions tackle technical debt that human engineers typically deprioritize: fixing flaky tests by running them thousands of times to reproduce failures, analyzing race conditions, and submitting patches to stabilize them. This is how Stripe maintains a test suite of over 3 million tests without drowning in maintenance overhead.
This is garbage collection for code quality. Human taste captured once, enforced continuously on every line. The key insight: the cleanup agents scale proportionally to code generation throughput. The more code agents write, the more cleanup agents run. This is the kind of self-balancing system that collapses if you try to do it manually but works naturally when automated.
Problem 5: I'm the bottleneck now
Here's the problem nobody anticipated: the agent is fast, reliable, and self-correcting, and now you can't review its output quickly enough.
The bottleneck shifts from code generation to human attention. You become the constraint. This creates a management problem that has nothing to do with technology and everything to do with how you structure your own time.
A spectrum is emerging. On one end, attended parallelization: you actively manage several agent sessions, checking in on each, redirecting when needed. This is how Hashimoto works with Claude Code and how I work with my own agents. You run maybe 3 to 5 sessions in parallel using git worktrees, context-switching between them as a reviewer. It's cognitively demanding but gives you tight control. Peter Steinberger, the solo developer behind OpenClaw, operates at the far edge of this mode: 5 to 10 agents simultaneously, 6,600 commits in a single month, shipping code he hasn't read line-by-line. But he's not reckless. He's the architectural gatekeeper. In his Discord, he never talks code, only architecture and big decisions.
On the other end, unattended parallelization: you post a task and walk away. The agent handles everything through CI and opens a PR when it's done. You re-enter the loop only at review time. This is Stripe's Minions model. An engineer tags the bot in Slack, the agent writes the code, passes CI within at most two rounds, and produces a PR ready for human review. No interaction in between. Stripe merges over 1,300 agent-generated PRs per week this way.
The gap between those two modes is not about model capability. It's about harness maturity. Stripe can run unattended because they spent years building developer infrastructure for humans: fast devbox provisioning (10 seconds), comprehensive test suites (3 million tests), extensive internal tooling. All of that investment transferred directly to agent productivity. The best preparation for unattended agents is, it turns out, just good engineering practices.
This is worth sitting with because it's counterintuitive. The best thing you can do right now to prepare for agents is not to study prompt engineering or LLM architectures. It's to invest in the things you were supposed to invest in anyway: clear architecture, good documentation, fast CI, honest feedback loops. The teams whose agents work are the teams that were already good at onboarding humans.
Stripe's team introduced a concept called blueprints that makes the orchestration layer concrete. A blueprint is a workflow that alternates between deterministic code nodes (linting, formatting, running specific tests) and flexible agent loops (the actual coding and reasoning). Deterministic gates sandwich the probabilistic LLM work. The model doesn't run the system. The system runs the model. That inversion is everything.
Problem 6: My team won't adopt any of this
The final problem is cultural, and it's the one most likely to kill adoption.
None of this happens by accident. Someone has to build the harness. Someone has to maintain the AGENTS.md . Someone has to write the custom linters, wire the observability stack, set up the CI gates. Greg Brockman recommended that every team designate an "agents captain," someone responsible for figuring out how agents fit into the team's workflow.
The investment compounds. Every AGENTS.md update prevents a class of future failures. Every custom linter teaches every future agent session. Every tool exposed via MCP makes every subsequent task faster. The upfront cost is significant, but the returns accelerate.
There's a deeper tension here that I've noticed in myself and seen echoed in the discourse. Engineers who love solving algorithmic puzzles tend to struggle with agent-native work. Engineers who love shipping products tend to adapt quickly. Peter Steinberger, the solo developer behind OpenClaw who runs 5 to 10 agents simultaneously, put it in terms of craft: he thinks of himself as a master carpenter working with subcontractors. He doesn't care who does the sawing and gluing. He cares about the design, the materials, and whether the final product meets his standard.
That framing requires letting go of something. The craft of writing code with your own hands is giving way to the craft of designing systems that write code. For a lot of engineers, that's an identity shift, not just a workflow change. Pretending it isn't is dishonest.
What nobody has figured out yet
I want to be specific about the open problems because the articles that last are the ones that are honest about what doesn't work.
- Behavioral verification at scale. Structural quality (linting, architecture, naming) is largely solvable with today's tools. Behavioral correctness (does the product actually do the right thing) is not. Google's DORA report found that 90% increases in AI adoption correlated with 91% increases in code review time. Linear measured 67.3% of AI-generated PRs being rejected versus 15.6% for manual code. The METR study found that experienced developers were 19% slower with AI tools while believing they were 20% faster. That's a 39 percentage-point perception gap. Generation is not the hard part. Verification is.
- The edit format problem. There is no standard, reliable way for agents to apply code changes. Different edit formats produce wildly different results across models. A researcher at can.ac showed that changing a single format variable improved 15 different models by 5 to 14 percentage points. Cursor built a separate 70-billion parameter model whose sole job is to merge edits correctly. JetBrains confirmed that no single format dominates across models and use cases. This is arguably the highest-leverage unsolved problem in the harness space, and it's weirdly underappreciated.
- Brownfield applicability. Every success story in this article involves either a greenfield project or a team that built infrastructure from scratch over many years. Applying harness engineering to a ten-year-old codebase with no architectural constraints, inconsistent testing, and patchy documentation is a much harder problem. Böckeler compared it to running a static analysis tool on a codebase that's never had one: you'd drown in alerts. Nobody has published a convincing playbook for this.
- Agent confidence calibration. Agents generate output with uniform confidence regardless of actual quality. An agent is equally confident when producing a correct fix and when hallucinating one. There's no built-in signal for "I'm not sure about this." Until agents can express uncertainty, humans have to treat every output with the same level of scrutiny, which defeats much of the efficiency gain.
- Token economics. Harness engineering as described by OpenAI involves massive iteration: background cleanup, parallel reviews, continuous observability queries. OpenAI has effectively infinite free inference. You don't. The token costs at scale are non-trivial, and almost nobody in the published discourse is honest about this.
The control system, seen whole
Zoom back out. What I've described is a closed-loop control system with six layers:
- Context engineering is the reference signal: what the agent should know and where to look.
- Architectural enforcement is the controller: what the agent can and cannot do.
- Observability is the sensor array: how the agent (and you) know whether it worked.
- Garbage collection is the error correction: how the system resists entropy over time.
- Management modes are the operating regime: how much human attention the loop requires.
- Cultural adoption is the power supply: without organizational buy-in, none of it runs.
Open-loop agent execution, just prompting and reviewing, is unstable. It works for small tasks the way open-loop control works for simple systems. But as complexity grows, as the codebase gets bigger, as more agents run in parallel, as the time horizon extends, the system drifts. You need closed-loop control to maintain coherence.
The convergence is what convinced me this framing is real and not just a convenient metaphor. OpenAI is a small squad doing greenfield. Stripe is a 10,000-person company with hundreds of millions of lines of Ruby. Hashimoto is a solo practitioner building a terminal emulator. Anthropic approached it from the research side. Boris Tane at Cloudflare came at it from observability. None of them referenced each other's work. They all built the same load-bearing structures. When five independent teams hit the same walls and build the same solutions, you're looking at something fundamental about the problem, not a trend.
Back to the product detail page
I started this article describing how I spent 80% of my time designing environments instead of writing prompts. I can now name what I was actually doing.
The inventory validation scripts were sensors. The structured output schemas were architectural constraints. The feedback loops that caught hallucinated product attributes were the error correction mechanism. The AGENTS.md I maintained for my chat agent's extended tools, documenting which tools to call in which order and what failure modes to watch for, was the reference signal. Even the frustration I felt about "not doing real work" was a signal. I was doing the real work. I just didn't have a frame for recognizing it.
I was building a control system. I just didn't have the vocabulary for it yet.
The vocabulary matters because it changes what you optimize for. When I thought I was "prompting," I kept trying to write better prompts. When I realized I was building a control system, I started investing in sensors (better validation), constraints (stricter schemas), and feedback loops (automated checks that fed results back to the agent). The improvement was immediate and compounding in a way that prompt tuning never was.
If you're using agents today and spending most of your time on the environment rather than the prompts, you're not doing it wrong. You're doing the thing. The question is whether you're doing it systematically, building each layer so it creates the foundation for the next, or ad hoc, patching problems as they appear without a model for why they keep appearing.
The control loop is the model. And the field is still early enough that the constraints you encode, the sensors you build, the feedback loops you close, will compound for a long time.
Build the loop. Close it. Let it run.
References
- OpenAI — "Harness engineering: leveraging Codex in an agent-first world" (Feb 2026). The article that started this conversation. Five months, zero manually-written code, ~1M lines.
https://openai.com/index/harness-engineering/ - Mitchell Hashimoto — "My AI Adoption Journey" (Feb 2026). Where the term "harness engineering" crystallized. Six-step progression from AI skeptic to productive agent user. The AGENTS.md-as-immune-system philosophy originates here.
https://mitchellh.com/writing/my-ai-adoption-journey - Stripe Engineering — "Minions: Stripe's one-shot, end-to-end coding agents" Parts 1 & 2 (Feb 2026). The most detailed public case study of enterprise-scale unattended agents. 1,300+ PRs/week, Toolshed MCP architecture, blueprints pattern, devbox infrastructure.
https://stripe.dev/blog/minions-stripes-one-shot-end-to-end-coding-agents - Anthropic — "Tips for building effective agents" and "Demystifying evals for AI agents" (2025-2026). The structured progress files pattern, JSON-over-Markdown for feature tracking, and the evaluation harness framework.
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents - Birgitta Böckeler / Martin Fowler — "Harness Engineering" (Feb 2026). The sharpest critical analysis. Identifies the behavioral verification gap. Asks whether harnesses become the new service templates.
https://martinfowler.com/articles/exploring-gen-ai/harness-engineering.html - mtrajan — "Harness Engineering Is Not Context Engineering" (Feb 2026). The key distinction: context engineering asks what the agent should see; harness engineering asks what the system should prevent, measure, and correct.
https://mtrajan.substack.com/p/harness-engineering-is-not-context - ignorance.ai
— "The Emerging Harness Engineering Playbook" (Feb 2026). Maps convergence across OpenAI, Stripe, Anthropic, Hashimoto, and Boris Tane. Identifies the four recurring practices and the attended-vs-unattended spectrum.
https://www.ignorance.ai/p/the-emerging-harness-engineering - can.ac
— "I Improved 15 LLMs at Coding in One Afternoon. Only the Harness Changed." (Feb 2026). Empirical proof that the harness matters more than the model. Single format variable improved 15 models by 5-14 percentage points.
https://blog.can.ac/2026/02/12/the-harness-problem/ - CodeScene — "Agentic AI Coding: Best Practice Patterns for Speed with Quality" (2026). The "AI operates in self-harm mode" observation. Code Health MCP server as mandatory agent feedback. Coverage gates as behavioral safeguards.
https://codescene.com/blog/agentic-ai-coding-best-practice-patterns-for-speed-with-quality - Mike Mason — "AI Coding Agents in 2026: Coherence Through Orchestration, Not Autonomy" (Jan 2026). The sobering data: METR study (19% slower, perceived 20% faster), LinearB (67.3% AI PR rejection rate), Cursor's hierarchical agent architecture.
https://mikemason.ca/writing/ai-coding-agents-jan-2026/ - Vadim Nicolai — "The Agent That Says No: Why Verification Beats Generation" (Feb 2026). Google DORA report data (90% AI adoption = 91% more review time). Proposes counterfactual analysis as a verification pattern.
https://vadim.blog/verification-gate-research-to-practice - Boris Tane (Cloudflare) — On the separation of planning and execution as the single most important practice. Referenced in the
ignorance.ai
playbook [7]. - OpenAI — "Unrolling the Codex agent loop" and "Unlocking the Codex harness: how we built the App Server" (2026). Technical details on the agent loop internals and the JSON-RPC App Server architecture.
https://openai.com/index/unrolling-the-codex-agent-loop/
and
https://openai.com/index/unlocking-the-codex-harness/ - Anthropic — "2026 Agentic Coding Trends Report" (Feb 2026). Industry-wide view of 8 trends reshaping software engineering.
https://resources.anthropic.com/hubfs/2026%20Agentic%20Coding%20Trends%20Report.pdf - epappas (DEV Community) — "The Agent Harness Is the Architecture (and Your Model Is Not the Bottleneck)" (Feb 2026). Technical deep-dive connecting harness engineering to Sculley et al.'s "Hidden Technical Debt in Machine Learning Systems."
https://dev.to/epappas/the-agent-harness-is-the-architecture-and-your-model-is-not-the-bottleneck-3bjd - Gergely Orosz / The Pragmatic Engineer — "Mitchell Hashimoto's new way of writing code" (Feb 2026). Interview covering Hashimoto's workflow, the identity shift in engineering, and the observation that git/GitHub may not survive the agentic era in current form.
https://newsletter.pragmaticengineer.com/p/mitchell-hashimoto